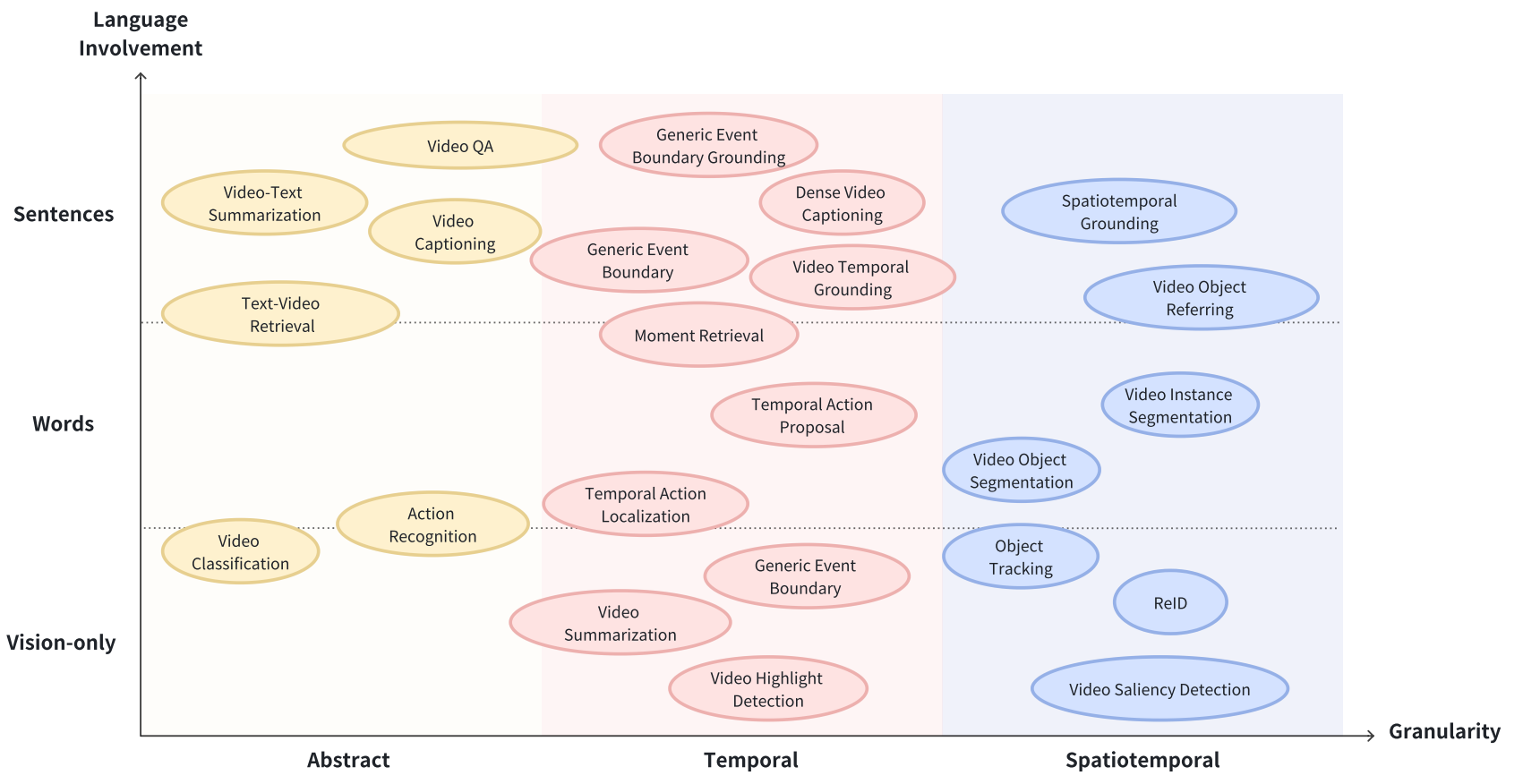
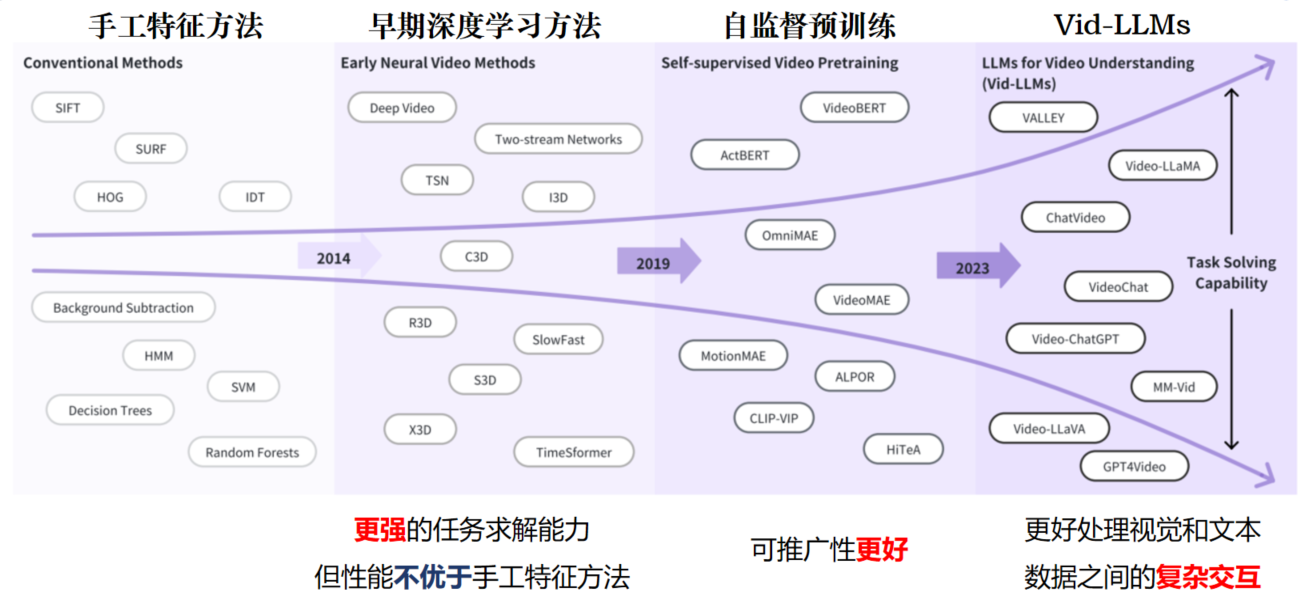
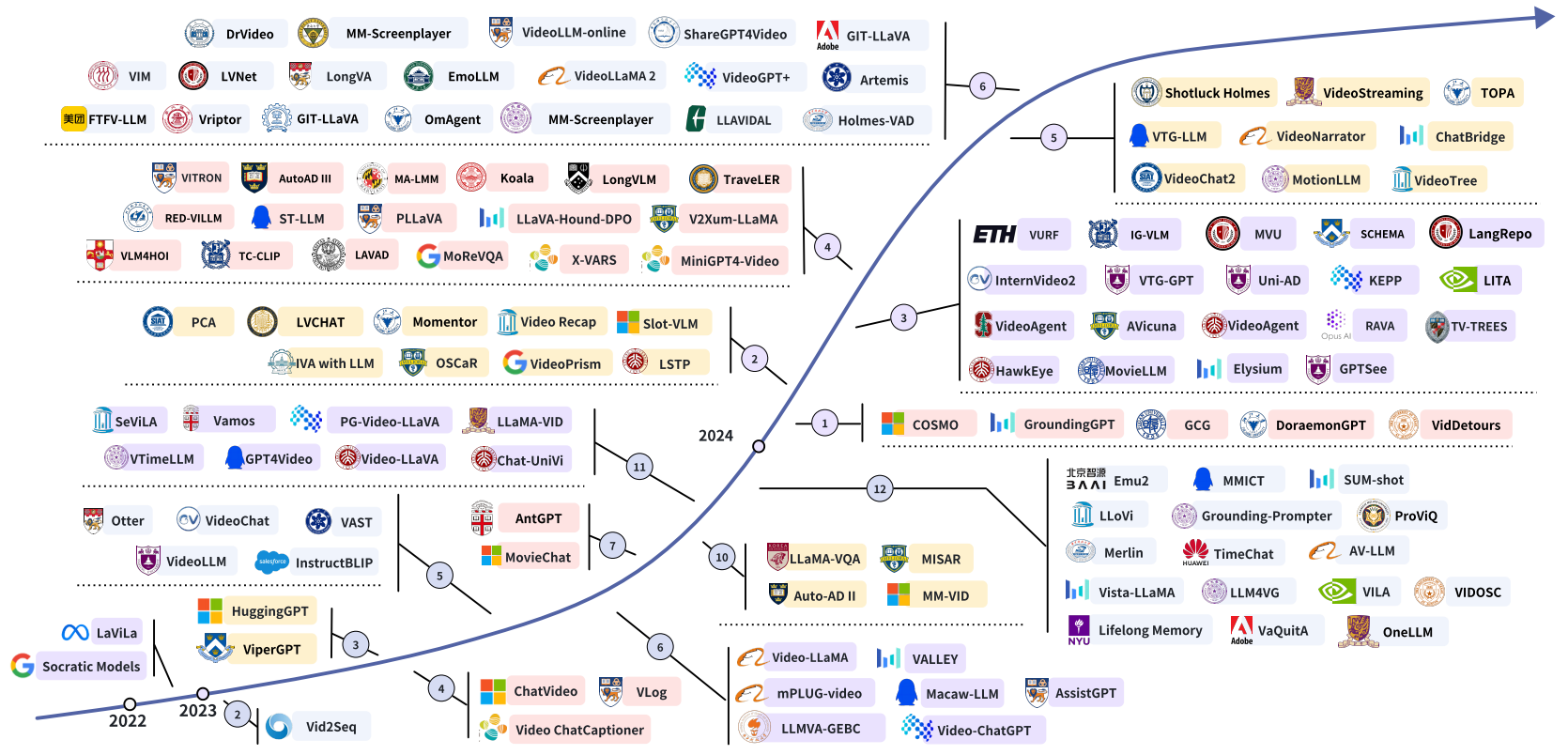
前言
标题:RE-Matching: A Fine-Grained Semantic Matching Method for Zero-Shot Relation Extraction 会议:ACL2023 网址:https://aclanthology.org/2023.acl-long.369 github:https://github.com/zweny/RE-Matching
研究背景
关系抽取:relation extraction是NLP的一个基本任务,目的是从非结构化文本中提取实体之间的关系。关系抽取有助于构建知识图谱,支持问答系统,提高信息检索的效率等。 例如,给定一个句子“史蒂夫:乔布斯创立了苹果公司”,关系抽取的任务就是识别出实体“史蒂夫乔布斯”和“苹果公司”,并识别出他们之间的关系“创立了”。
动机
■关系抽取的挑战: 由于新关系的快速增长,为每个关系不断标注数据既昂贵又不切实际。因此,如何有效地进行零样本关系抽取(ZeroRE) ,即从未见过的关系中提取关系,成为了一个重要的研究问题。 ■关系抽取的现状和不足: 目前,主流的零样本关系抽取方法是基于语义匹配的,即给定一个输入实例和一段关系描述,计算它们之间的语义相似度。没有考虑关系数据的匹配模式,即输入中的实体应该与描述中的类别进行精确匹配,而与关系无关的上下文应该在匹配时被忽略。
创新
■研究创新: 1.本文提出了一种用于零样本关系抽取的细粒度语义匹配方法。 2.该方法显式地建模了关系数据的匹配模式,将句子级别的相似度分解为实 体和上下文匹配分数。
- 该方法还设计了一个上下文提炼模块,使用特征蒸馏方式,用于识别和减 少与关系无关的特征对上下文匹配的负面影响。
- 细粒度语义匹配:指将整体的句子级别的相似度分解为更细粒度的相似度,如词汇级别或短语级别的相似度,从而更准确地捕捉文本之间的语义关系。细粒度语义匹配通常需要对文本进行编码和交互两个步骤。编码步骤是将文本转换为数值向量(也称为嵌入),交互步骤是利用不同的机制(如点积、余弦、注意力等)来计算文本向量之间的相似度分数。细粒度语义匹配在自然语言处理中有很多应用,如问答、文本蕴含、关系抽取等。
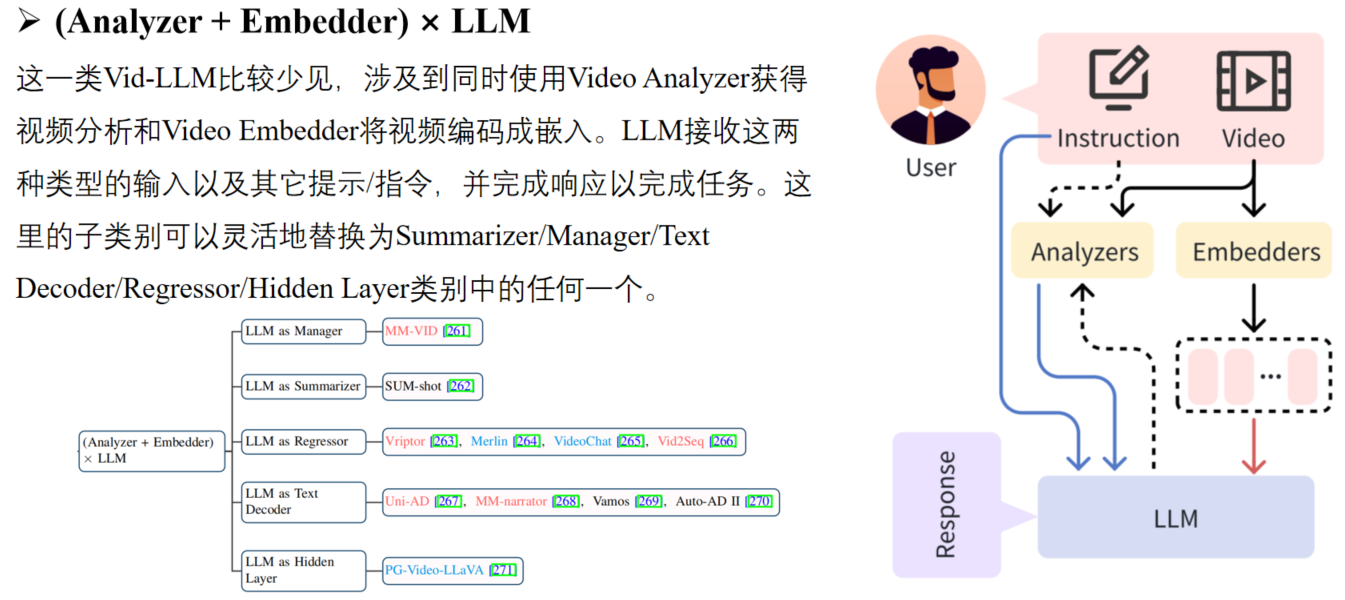
- 显示建模:“{实体1}是{实体2}的创始人”,然后用这个模式去匹配文本中的信息
 Figure1:一个关系数据匹配模式的例子。输入的句子包含一个给定的实体对,该实体对应该匹配对应的上位概念(通常是实体类型)。上下文描述了实体之间的关系,包含了与关系无关的冗余信息,在进行匹配时应该被忽略。
关系属于有独特的匹配模式。这是一般的匹配方法没有明确考虑到的(fig 1):输入中的实体应该与他们在描述中的上位概念完全匹配,公司就与公司匹配,地点就与地点匹配。冗余信息则需要过滤。不过问题是:冗余成分在匹配时由于缺乏显示注释,模型要学会识别他们很困难。
Figure1:一个关系数据匹配模式的例子。输入的句子包含一个给定的实体对,该实体对应该匹配对应的上位概念(通常是实体类型)。上下文描述了实体之间的关系,包含了与关系无关的冗余信息,在进行匹配时应该被忽略。
关系属于有独特的匹配模式。这是一般的匹配方法没有明确考虑到的(fig 1):输入中的实体应该与他们在描述中的上位概念完全匹配,公司就与公司匹配,地点就与地点匹配。冗余信息则需要过滤。不过问题是:冗余成分在匹配时由于缺乏显示注释,模型要学会识别他们很困难。
方法介绍
任务定义和方法概述
■任务定义: 指在零样本关系抽取(ZeroRE) 中,目标是从已知关系Rs学习并推广到未知关系Ru。这两个集 合是不相交的,即Rs∩Ru = 0,并且只有在训练阶段才能获得已知关系Rs的样本。 ■方法概述: 提出了一种细粒度语义匹配方法,该方法显式地建模了关系数据的匹配模式,将句子级别的相 似度分解为实体和上下文匹配分数。此外,我们设计了一个特征蒸馏模块,以自适应地识别关 系无关的特征,并减少它们对上下文匹配的负面影响。
匹配模型
■训练集: D = {((xi, ei1,ei2,Yi,di))|i= 1….N},一共N个样本 ■样本组成:xi是输入实例,ei1,ei2是 目标实体对,yi 属于Rs,di是y;对 应的关系描述 ■优化匹配模型: M(x,e1,e2,d)→ s∈R 衡量方法:计算x与d之间的语义相似度。将输入和每个候选关系描述转化为数值向量,然后 通过比较向量相似度(如余弦相似度cosinesimilarity)来确认最可能对应的关系描述。 测试:将匹配模型M迁移学习,抽取未知的关系Ru . 有一个样本(x;,ei1, eiz),它表示R中的一个未见过的关系。找到与输入样本相似度最高的来进 行预测。
细粒度语义匹配方法
[传统的语义匹配方法通常将编码和匹配视为一个整体的过程。这些方法主要依赖于预定义的规则、知识图谱、本体或者语料库来进行语义匹配]
在这些方法中,文本首先被编码为数值向量(也称为嵌入),然后这些向量被用来计算文本之间的相似度。然而,这些方法通常没有显式地考虑文本中的细粒度信息,如词汇级别或短语级别的相似度,因此可能无法准确地捕捉文本之间的语义关系。此外,这些方法的性能受到手动定义规则的影响,对非线性灰度失真的抵抗力较弱,匹配效率和准确性较差。
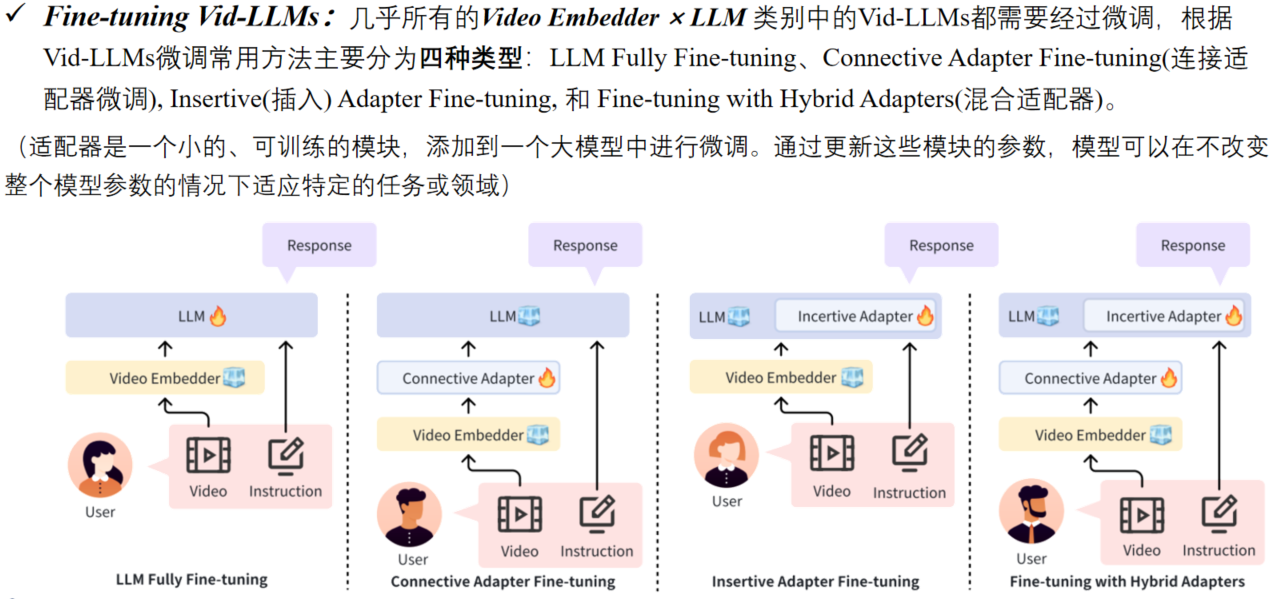
Figure2:
 ■左侧: 输入实例与关系描述分开编码。编码模块负责提取输入实例和关系描述中的实体和
上下文信息, 将其编码为固定长度的表示,以便进行后续的细粒度匹配。
■中间:实体和上下文匹配计算相似度。将句子级别的相似度分解为实体匹配分数和上下文匹配分数。
■右侧:设计一个特征蒸馏模块减少无关组件对上下文匹配的影响。
■左侧: 输入实例与关系描述分开编码。编码模块负责提取输入实例和关系描述中的实体和
上下文信息, 将其编码为固定长度的表示,以便进行后续的细粒度匹配。
■中间:实体和上下文匹配计算相似度。将句子级别的相似度分解为实体匹配分数和上下文匹配分数。
■右侧:设计一个特征蒸馏模块减少无关组件对上下文匹配的影响。
输入-描述编码模块
 输入实例与关系描述
分开编码。
1.将实例和候选 描述中的实体提取出来。将其编码为固定长度向量。
2.采用Sentence - BERT来扩展候选描述d的头尾实体dh,dt
3.采用BERT编码输入实例x的上下文和实体xih,xti表示。
4.计算复杂度从0(nm) →o(n +m)
输入实例与关系描述
分开编码。
1.将实例和候选 描述中的实体提取出来。将其编码为固定长度向量。
2.采用Sentence - BERT来扩展候选描述d的头尾实体dh,dt
3.采用BERT编码输入实例x的上下文和实体xih,xti表示。
4.计算复杂度从0(nm) →o(n +m)
- 扩展头尾实体描述的目的是为了丰富实体信息,从而提高实体匹配的效果。在关系数据中,实体匹配是一个重要的组成部分,它要求输入中的实体与描述中的超类精确匹配。然而,在描述中,通常只有一两个词来标识实体类型,这可能导致实体信息不足,从而影响匹配的准确性。
- 为了解决这个问题,我们探索了不同的方法来自动构建和扩展实体描述,如使用同义词、基于规则的模板填充等。这些方法可以增加实体描述的丰富性和流畅性,从而刺激预训练模型输出高质量的实体表示。实验结果表明,使用这些方法可以显著提高匹配F1分数,相比于只使用原始的关键词方法
■关系描述编码器: 例如”headquartered. in” (“the headquarters of an organization is located in a place”)这个描述被编码成一个表示d,我们可以通过比较输入实例和这个表示d的相似度来判断输入实例是否具有”headquartered_ in”这个关系。
■关键词:可以直接使用d中的实体类型(entity type)作为实体描述。比如headquartered. _in, dh是organization, dt 是place
■同义词:可以使用Wikidata提取上义词的同义词。比如d’是“organization, institution, company”
■基于规则的模板填充
■输入实例编码器:输入实例xi = {W1, we…. wn}用4个特殊token :“[Eh], [\Eh], [Et], [\Et]”。
插入到头实体ei1和尾实体ei2中。通过隐藏层+MaxPool得到头尾实体表示。

上下文关系特征蒸馏

 梯度反转层:
梯度反转层:
 关系特征蒸馏层
关系特征蒸馏层
 细粒度匹配训练:
细粒度匹配训练:

实验
数据集:
1、FewRel:从维基百科收集的少样本关系分类数据集,包含80个关系,每个关系包含700
个句子。
2、Wiki-ZSL: 源自维基数据知识库,由93,383个句子组成,包含113种关系类型。
验证集:
随机选取5个关系作为验证集,再随机选择m∈{5,10,15}个作为测试集中的未知关系,其
余作为训练集的已知关系。
模型: R-BERT、ESIM、ZS-BERT、 PromptMatch、 REPrompt
使用Bert-base-uncased作为输入实例编码器,fixed sentence-Bert作为关系描述编码器
实验一:
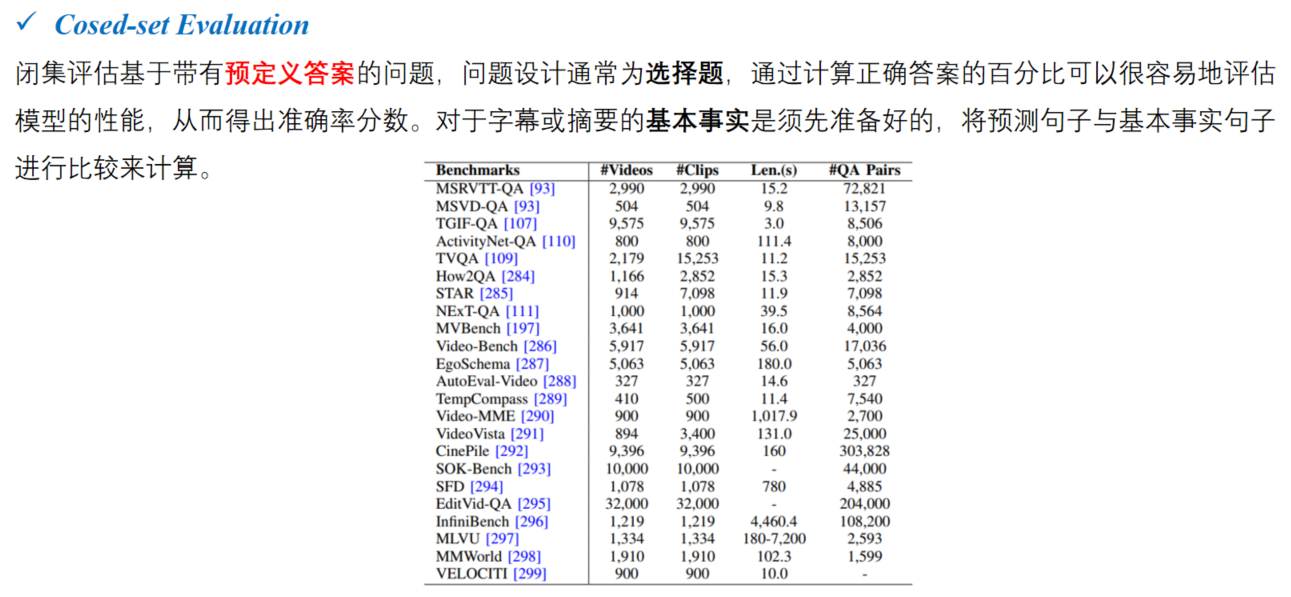
 1.ZS-Bert为ZeroRE,但siamese. scheme限制了输入和关系描述之间的细粒度交互,因此性能次优。
2.PromptMatch使用全编码方案,可以通过自注意力隐式建模细粒度交互。但所提出的方法仍然能够超越它。一个可能的原因是关系匹配模式作为一种归纳偏差,缓解了对训练集中所见关系的过拟合,因此我们的模型具有更好的泛化性。
消融实验:
1.ZS-Bert为ZeroRE,但siamese. scheme限制了输入和关系描述之间的细粒度交互,因此性能次优。
2.PromptMatch使用全编码方案,可以通过自注意力隐式建模细粒度交互。但所提出的方法仍然能够超越它。一个可能的原因是关系匹配模式作为一种归纳偏差,缓解了对训练集中所见关系的过拟合,因此我们的模型具有更好的泛化性。
消融实验:
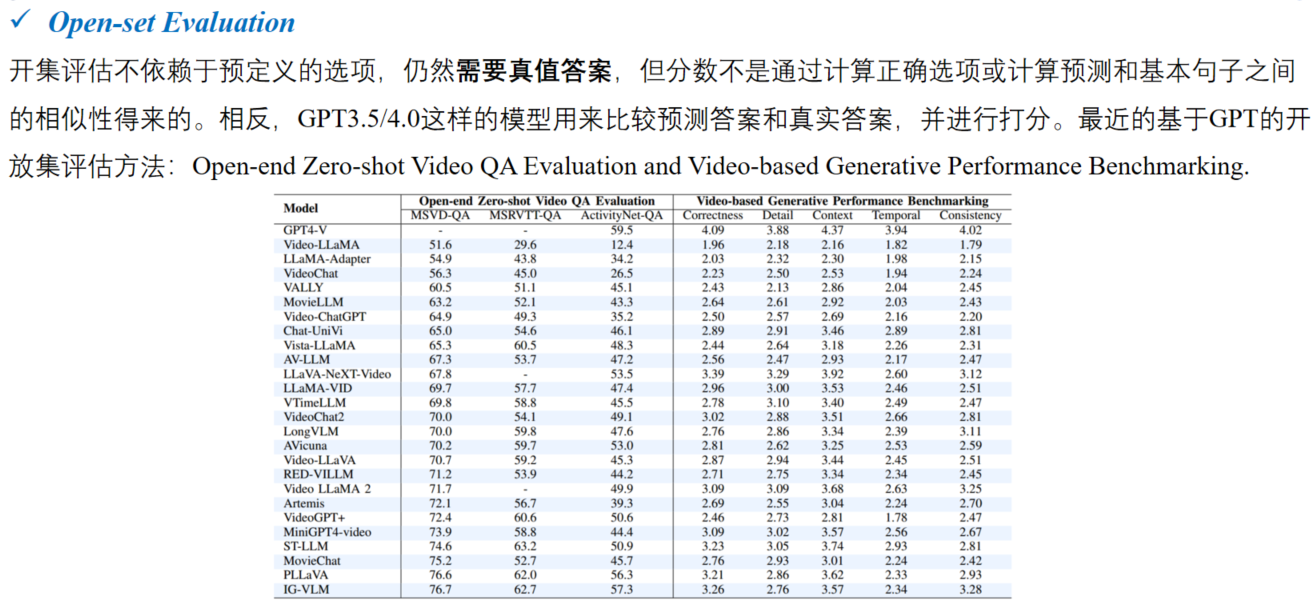
 如果去除上下文蒸馏模块(w/o Proi) ,匹配性能下降。说明上下文中不相关的关系信息会干扰关系数据的匹配,而在蒸馏模块中进行投影可以有效降低这种影响。
实体信息在在关系数据(见w/o Ent)中发挥着重要的作用。显式地建模实体与其上位概念之间的匹配,显著地提高了模型的性能。
作为两个至关重要的组成部分,当上下文蒸馏和实体匹配都被移除(即w/oboth)时,匹配就退化为句子级别的匹配,性能会受到严重影响
如果去除上下文蒸馏模块(w/o Proi) ,匹配性能下降。说明上下文中不相关的关系信息会干扰关系数据的匹配,而在蒸馏模块中进行投影可以有效降低这种影响。
实体信息在在关系数据(见w/o Ent)中发挥着重要的作用。显式地建模实体与其上位概念之间的匹配,显著地提高了模型的性能。
作为两个至关重要的组成部分,当上下文蒸馏和实体匹配都被移除(即w/oboth)时,匹配就退化为句子级别的匹配,性能会受到严重影响
前言 标题:RE-Matching: A Fine-Grained Semantic Matching Method for Zero-Shot Relation Extraction 会议:ACL2023 网址:https://aclanthology.org/2023.acl-long.369 github:https://github.com/zweny/RE-Matching
研究背景 关系抽取:relation extraction是NLP的一个基本任务,目的是从非结构化文本中提取实体之间的关系。关系抽取有助于构建知识图谱,支持问答系统,提高信息检索的效率等。 例如,给定一个句子“史蒂夫:乔布斯创立了苹果公司”,关系抽取的任务就是识别出实体“史蒂夫乔布斯”和“苹果公司”,并识别出他们之间的关系“创立了”。
动机 ■关系抽取的挑战: 由于新关系的快速增长,为每个关系不断标注数据既昂贵又不切实际。因此,如何有效地进行零样本关系抽取(ZeroRE) ,即从未见过的关系中提取关系,成为了一个重要的研究问题。 ■关系抽取的现状和不足: 目前,主流的零样本关系抽取方法是基于语义匹配的,即给定一个输入实例和一段关系描述,计算它们之间的语义相似度。没有考虑关系数据的匹配模式,即输入中的实体应该与描述中的类别进行精确匹配,而与关系无关的上下文应该在匹配时被忽略。
创新 ■研究创新: 1.本文提出了一种用于零样本关系抽取的细粒度语义匹配方法。 2.该方法显式地建模了关系数据的匹配模式,将句子级别的相似度分解为实 体和上下文匹配分数。
该方法还设计了一个上下文提炼模块,使用特征蒸馏方式,用于识别和减
少与关系无关的特征对上下文匹配的负面影响。
细粒度语义匹配:指将整体的句子级别的相似度分解为更细粒度的相似度,如词汇级别或短语级别的相似度,从而更准确地捕捉文本之间的语义关系。细粒度语义匹配通常需要对文本进行编码和交互两个步骤。编码步骤是将文本转换为数值向量(也称为嵌入),交互步骤是利用不同的机制(如点积、余弦、注意力等)来计算文本向量之间的相似度分数。细粒度语义匹配在自然语言处理中有很多应用,如问答、文本蕴含、关系抽取等。
显示建模:“{实体1}是{实体2}的创始人”,然后用这个模式去匹配文本中的信息
Figure1:一个关系数据匹配模式的例子。输入的句子包含一个给定的实体对,该实体对应该匹配对应的上位概念(通常是实体类型)。上下文描述了实体之间的关系,包含了与关系无关的冗余信息,在进行匹配时应该被忽略。 关系属于有独特的匹配模式。这是一般的匹配方法没有明确考虑到的(fig 1):输入中的实体应该与他们在描述中的上位概念完全匹配,公司就与公司匹配,地点就与地点匹配。冗余信息则需要过滤。不过问题是:冗余成分在匹配时由于缺乏显示注释,模型要学会识别他们很困难。 方法介绍 任务定义和方法概述 ■任务定义: 指在零样本关系抽取(ZeroRE) 中,目标是从已知关系Rs学习并推广到未知关系Ru。这两个集 合是不相交的,即Rs∩Ru = 0,并且只有在训练阶段才能获得已知关系Rs的样本。 ■方法概述: 提出了一种细粒度语义匹配方法,该方法显式地建模了关系数据的匹配模式,将句子级别的相 似度分解为实体和上下文匹配分数。此外,我们设计了一个特征蒸馏模块,以自适应地识别关 系无关的特征,并减少它们对上下文匹配的负面影响。
匹配模型 ■训练集: D = {((xi, ei1,ei2,Yi,di))|i= 1…N},一共N个样本 ■样本组成:xi是输入实例,ei1,ei2是 目标实体对,yi 属于Rs,di是y;对 应的关系描述 ■优化匹配模型: M(x,e1,e2,d)→ s∈R 衡量方法:计算x与d之间的语义相似度。将输入和每个候选关系描述转化为数值向量,然后 通过比较向量相似度(如余弦相似度cosinesimilarity)来确认最可能对应的关系描述。 测试:将匹配模型M迁移学习,抽取未知的关系Ru . 有一个样本(x;,ei1, eiz),它表示R中的一个未见过的关系。找到与输入样本相似度最高的来进 行预测。
细粒度语义匹配方法
[传统的语义匹配方法通常将编码和匹配视为一个整体的过程。这些方法主要依赖于预定义的规则、知识图谱、本体或者语料库来进行语义匹配]
在这些方法中,文本首先被编码为数值向量(也称为嵌入),然后这些向量被用来计算文本之间的相似度。然而,这些方法通常没有显式地考虑文本中的细粒度信息,如词汇级别或短语级别的相似度,因此可能无法准确地捕捉文本之间的语义关系。此外,这些方法的性能受到手动定义规则的影响,对非线性灰度失真的抵抗力较弱,匹配效率和准确性较差。
Figure2:
■左侧: 输入实例与关系描述分开编码。编码模块负责提取输入实例和关系描述中的实体和
上下文信息, 将其编码为固定长度的表示,以便进行后续的细粒度匹配。
■中间:实体和上下文匹配计算相似度。将句子级别的相似度分解为实体匹配分数和上下文匹配分数。
■右侧:设计一个特征蒸馏模块减少无关组件对上下文匹配的影响。
输入-描述编码模块
输入实例与关系描述 分开编码。 1.将实例和候选 描述中的实体提取出来。将其编码为固定长度向量。 2.采用Sentence - BERT来扩展候选描述d的头尾实体dh,dt 3.采用BERT编码输入实例x的上下文和实体xih,xti表示。 4.计算复杂度从0(nm) →o(n +m)
扩展头尾实体描述的目的是为了丰富实体信息,从而提高实体匹配的效果。在关系数据中,实体匹配是一个重要的组成部分,它要求输入中的实体与描述中的超类精确匹配。然而,在描述中,通常只有一两个词来标识实体类型,这可能导致实体信息不足,从而影响匹配的准确性。
为了解决这个问题,我们探索了不同的方法来自动构建和扩展实体描述,如使用同义词、基于规则的模板填充等。这些方法可以增加实体描述的丰富性和流畅性,从而刺激预训练模型输出高质量的实体表示。实验结果表明,使用这些方法可以显著提高匹配F1分数,相比于只使用原始的关键词方法
■关系描述编码器: 例如”headquartered. in” (“the headquarters of an organization is located in a place”)这个描述被编码成一个表示d,我们可以通过比较输入实例和这个表示d的相似度来判断输入实例是否具有”headquartered_ in”这个关系。
■关键词:可以直接使用d中的实体类型(entity type)作为实体描述。比如headquartered. _in, dh是organization, dt 是place
■同义词:可以使用Wikidata提取上义词的同义词。比如d’是“organization, institution, company”
■基于规则的模板填充
■输入实例编码器:输入实例xi = {W1, we… wn}用4个特殊token :“[Eh], [\Eh], [Et], [\Et]”。
插入到头实体ei1和尾实体ei2中。通过隐藏层+MaxPool得到头尾实体表示。
上下文关系特征蒸馏
梯度反转层:
关系特征蒸馏层
细粒度匹配训练:
实验
数据集:
1、FewRel:从维基百科收集的少样本关系分类数据集,包含80个关系,每个关系包含700
个句子。
2、Wiki-ZSL: 源自维基数据知识库,由93,383个句子组成,包含113种关系类型。
验证集:
随机选取5个关系作为验证集,再随机选择m∈{5,10,15}个作为测试集中的未知关系,其
余作为训练集的已知关系。
模型: R-BERT、ESIM、ZS-BERT、 PromptMatch、 REPrompt
使用Bert-base-uncased作为输入实例编码器,fixed sentence-Bert作为关系描述编码器
实验一:
1.ZS-Bert为ZeroRE,但siamese. scheme限制了输入和关系描述之间的细粒度交互,因此性能次优。 2.PromptMatch使用全编码方案,可以通过自注意力隐式建模细粒度交互。但所提出的方法仍然能够超越它。一个可能的原因是关系匹配模式作为一种归纳偏差,缓解了对训练集中所见关系的过拟合,因此我们的模型具有更好的泛化性。 消融实验:
如果去除上下文蒸馏模块(w/o Proi) ,匹配性能下降。说明上下文中不相关的关系信息会干扰关系数据的匹配,而在蒸馏模块中进行投影可以有效降低这种影响。
实体信息在在关系数据(见w/o Ent)中发挥着重要的作用。显式地建模实体与其上位概念之间的匹配,显著地提高了模型的性能。
作为两个至关重要的组成部分,当上下文蒸馏和实体匹配都被移除(即w/oboth)时,匹配就退化为句子级别的匹配,性能会受到严重影响